
通过一道题浅谈php反序列化字符逃逸
moeCTF2022的一道题目,通过此题讲一下反序列化字符逃逸——值逃逸。
一些文章是以字符串逃逸的位置来分类的
1 | 键逃逸 |
我这里是值逃逸,但是讨论的情况是字符串的增加和减少。
原理是,序列化字符串依据字段内容长度来判断字段内容的归属,而不是依据双引号。
baby_unserialize(增)
index.php
1 |
|
a.php
1 |
|
睡前想起来的,这里的session是绕不过的,但是在
序列化->反序列化
这中间,这个小黑子进行了如下操作
1 | $emo = str_replace('aiyo', 'ganma', serialize($moe)); |
aiyo是4个字符,ganma是5个字符。
正常序列化出一个字符串是这样的
1 | O:6:"moectf":3:{s:1:"a";s:3:"___";s:1:"b";s:3:"___";s:5:"token";s:5:"baizi";} |
token为最后一个值,既然如此,思路很清晰,构造aiyo,把最后一个token属性挤出去,换上我们构造的token。
$b处构造
构造的token为
1 | ";s:5:"token";s:5:"baizi";} |
长度为27
最后要加一个” 把原来的字符串闭合上
payload:
1 | ?r=1&s=aiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyo";s:5:"token";s:5:"baizi";} |
$a处构造
构造的token为
1 | ";s:1:"b";s:1:"5";s:5:"token";s:5:"heizi";} |
长度为43
payload:
1 | ?r=aiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyoaiyo";s:1:"b";s:1:"5";s:5:"token";s:5:"baizi";}&s=5 |
因为这里都是借助
1 | public function __construct($r,$s){ |
所以不能够使用键逃逸,键值不可控,但是其实原理都是一样的,只是要挤兑的值不同。
本地测试源码
1 |
|
魔改baby_unserialize(减)
上面讲得是替换的字符串增加字符的,现在试试字符串长度减少的,稍微麻烦点,因为需要考虑的细节更多,相对而言 增的逃逸更加粗暴。
直接在我的测试源码修改
1 |
|
现在是把ganma替换为aiyo(没错,我也是小黑子 o( ̄ε ̄*)
首先依然放出一个正常的序列化字符串
1 | O:6:"moectf":3:{s:1:"a";s:3:"___";s:1:"b";s:3:"___";s:5:"token";s:5:"heizi";} |
如果把字符串长度增加的replace比作挤兑,字符串长度减小的replace就是修补。把原来的字符串的内容破坏掉,再用自己构造的内容修好。
字符串长度减小的替换应该更常见一些,经常是替换过滤字符为空。
1 | O:6:"moectf":3:{s:1:"a";s:3:"___";s:1:"b";s:3:"___";s:5:"token";s:5:"heizi";} |
如果构造a处的逃逸则意味着从
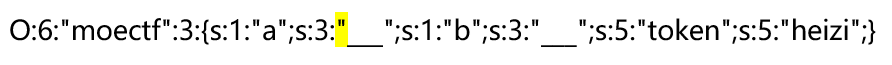
黄色标注的双引号开始吞噬后面的字符,即从对应的字段值内容开始吞噬。吞噬的意思是,这一部分值都变为变量的内容。既然是吞噬了,那就破坏了原有的序列化字符串的结构,所以需要在后面再构造一个新的内容作为替换,补上破坏的字符串结构。但是这个新内容不能和吞噬部分放在一个变量,新内容加进去多少字符串,变量的长度就加几,无论怎样,新内容始终被包裹在这个变量内。
注意事项
1、要保证格式的正确
比如吞的时候不能只吞一半,导致双引号闭合不上,或者缺少; }等
1 | O:6:"moectf":3:{s:1:"a";s:3:"___";s:1:"b";s:3:"___";s:5:"token";s:5:"heizi";} |
这意味着,构造时,必须考虑到开始的双引号的闭合,同时还需要考虑到双引号与我们构造的替换payload之间的字段名属性、内容,以及字段内容的属性
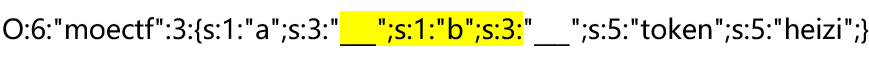
即图中这一块,去掉以后是这样的:
1 | O:6:"moectf":3:{s:1:"a";s:3:""___";s:5:"token";s:5:"heizi";} |
这里面$b的内容是我打算用来替换后面的token的payload,所以以$b字段内容的双引号作为闭合。这样后面的payload就不被双引号包裹,逃逸出来了,只需要再构造一个正确的序列化字符串内容就能够被反序列化解析。
1 | ;s:1:"b";s:3:"489";s:5:"token";s:5:"baizi";} |
前面之所以加入;也是为了保证格式,闭合$a的 ; 被吞掉了,所以需要补上。
2、吞的时候要保证序列化对象属性个数对的上
附上一张对象序列化字符串格式

更多详细内容可参考PHP 序列化(serialize)格式详解(Neatstudio.COM)
1 | O:6:"moectf":3:{s:1:"a";s:3:"___";s:1:"b";s:3:"___";s:5:"token";s:5:"heizi";} |
比如上述,属性的个数就是3。
$a处构造
1 | ?r=ganmaganmaganmaganmaganmaganmaganmaganmaganmaganmaganmaganmaganmaganmaganma&s=;s:1:"b";s:3:"489";s:5:"token";s:5:"baizi";} |
ganma的数量为吞噬的属性字符串长度
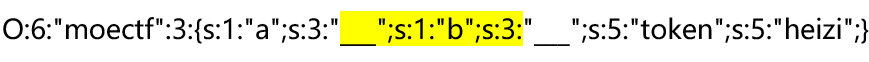
也就是这一段。

$b处构造
$b应该构造不了吧 ◐▽◑
如果从$b开始吞噬,后面没有地方能够放我们的payload了,token不可控。
可得出使用前提
使用前提
字符串减少的逃逸需要至少两处payload可控,一处用于吞噬字符串,一处用于替换原有的序列化字符串。
总结
字符串增加的逃逸可理解为把构造的变量值后面的字符挤兑掉,替换为变量值后面的用于替换的payload,需要计算的是右边双引号到末尾的长度(和要替换的payload一致)。只需一处即可完成。
字符串减少的逃逸可理解为序列化字符串的修补过程,先吞噬掉原来的结构,再用替换的payload补上这部分结构,需要计算的是左边双引号到替换payload的左边双引号长度,需要构造两处。